안녕하세요, Addeep입니다.
Addeep이 고도화 중인 GPR Integrated Latent Space는 사용자, 콘텐츠, 브랜드, 상품, 장면을 하나의 의미 기반 구조로 정렬하여 각 모달(이미지·영상·음원·텍스트) 생성 과정에 직접 반영하는 독자적 기술 체계입니다.
이 글에서는, 그중에서도 “모달별 Latent 구조를 어떻게 정의하고, 이를 GPR z-space와 어떻게 연결할 것인가”라는 핵심 연구 영역을 다루고자 합니다.
Addeep은 기존 기술계의 파편화된 접근 방식 – 텍스트/이미지/영상/오디오를 별개 시스템으로 다루는 방식을 넘어, “하나의 의미 세계관 위에서 멀티모달 생성이 유기적으로 정렬되는 시스템”을 연구하고 있습니다.
1. GPR Integrated Latent Space의 역할과 구성 요소
Addeep의 GPR z-space는 단순한 임베딩 공간이 아니라, 한 장면(scene)을 구성하는 의미적 단위들이 서로 어떻게 연결되고, 어떤 방식으로 생성 과정에 영향을 미치는지를 직접적으로 모델링하는 구조입니다.
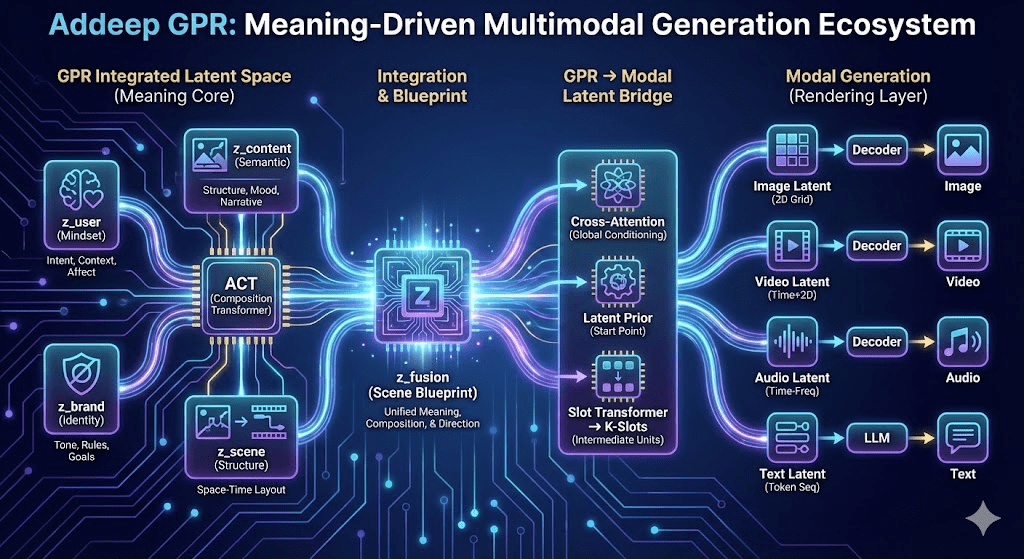
각 구성 요소는 다음과 같은 역할을 수행합니다.
1.1 z_user — 유저 마인드셋(User Mindset State)
z_user는 단순한 개인 취향 정보가 아니라,
사용자의 의도(intent), 관심도(interest), 정서 상태(affect),
그리고 상황적 맥락(contextual tendency)을 장·단기적으로 통합하여 표현하는 벡터입니다.
Addeep은 사용자가 만드는 콘텐츠 패턴, 감정적 반응, 시청 행동, 작성 문맥, 상호작용 흐름 등을 장기간 축적하여 사용자별 “마인드맵”을 유지합니다.
z_user는 다음과 같은 의미적 요소를 포함하도록 설계되어 있습니다.
- 사용자가 선호하는 이야기 구조, 전개 속도, 감정 톤
- 사용자의 일상 패턴(예: ‘밤에 감성 콘텐츠를 즐기는 경향’)
- 브랜드·상품에 대한 친화도와 반응 패턴
- 시점별 변동하는 감정 및 동기
- 콘텐츠 참여·선택 방식에서 추론한 기저 의도
즉, z_user는 Addeep이 생성하는 모든 콘텐츠의 “개인화의 핵심 센서”입니다.
이미지/영상/음악/텍스트 생성 단계에서 사용자 맞춤형 톤, 배경, 색감, 메시지가 자연스럽게 반영되도록 하는 중심 신호입니다.
1.2 z_content — 콘텐츠 의미 구조(Content Semantic State)
z_content는 특정 콘텐츠가 담고 있는 장면 정보와 의미적 구조를 표현합니다.
이 벡터에는 다음과 같은 요소가 포함됩니다.
- 장면의 구성요소(인물·물체·공간·소품)
- 콘텐츠의 감정적 분위기와 스타일
- 내러티브 흐름(도입·전개·전환·마무리)
- 시각적 콘셉트 및 세계관 요소
- 유저가 어떤 포인트에서 반응했는지에 대한 의미 신호
z_content는 원본 UGC나 브이로그, 사진·텍스트 등으로부터 추출되며
최종 생성 콘텐츠가 “원본의 세계관을 유지하면서 확장되도록” 돕습니다.
1.3 z_brand — 브랜드·상품 의미 구조(Brand Identity State)
z_brand는 브랜드 또는 상품이 유지해야 하는 의미적 정체성을 표현합니다.
Addeep GPR에서 z_brand는 단순한 로고 인식 수준이 아닙니다.
브랜드가 원하는 톤·세계관·제약 조건·표현 규칙까지 포함하는 구조입니다.
예:
- 브랜드 고유 색감·질감·연출 톤
- 전달하고자 하는 메시지의 톤(신선함/신뢰/활기 등)
- 화면에서 보여줄 수 있는 크기·비율·노출 방식
- 브랜드가 선호하는 스토리 포맷
- 브랜드가 금지하는 표현·연출 규칙
광고결합 스마트콘텐츠에서 z_brand는 콘텐츠의 자연스러움을 유지하면서 브랜드 목적을 달성하는 데 핵심적인 역할을 합니다.
1.4 z_scene — 장면 구조(Scene Structural State)
z_scene은 특정 콘텐츠의 공간적·시간적 배치 구조를 표현합니다.
- 어떤 객체가 어디에 위치해야 하는지
- 어떤 감정 흐름이 시간 축을 따라 변화하는지
- 어떤 장면 전환 구조를 가지는지
- 어떤 연출 포인트에서 효과·음향·텍스트가 등장해야 하는지
이 벡터는 최종적으로 생성되는 이미지·영상·오디오·텍스트 구조와
직접적으로 연결되는 설계도 역할을 수행합니다.
1.5 z_fusion — 의미·구도·연출을 통합한 장면 설계도(Scene Blueprint)
ACT(Addeep Composition Transformer)는
z_user, z_content, z_brand, z_scene을 받아
하나의 일관된 장면 설계도(z_fusion)를 생성합니다.
z_fusion은 다음과 같은 요소를 포함하도록 설계됩니다.
- 색감·조명·톤
- 감정의 기조
- 브랜드 노출 전략
- 장면에서 강조해야 하는 의미 요소
- 레이아웃 배치 관련 힌트
- 시간 축에서의 연출 시점
- 텍스트·음향이 들어갈 자리
z_fusion은 Addeep 생성 생태계 전체의 핵심 단일 표현(single representation)입니다.
각 모달 디코더가 이 정보를 바탕으로
“서로 다른 모달이지만 하나의 장면처럼 보이는 결과물을 만들도록” 돕습니다.
2. 왜 모달별 Latent가 필요한가
GPR z-space는 의미 중심 구조이며,
이미지·영상·음원·텍스트 디코더는 물리적 구조(픽셀·프레임·주파수·토큰)를 요구합니다.
예:
- 이미지 → 2D 그리드 구조
- 영상 → 2D + 시간 구조
- 오디오 → 시간–주파수 구조
- 텍스트 → 이산 토큰 시퀀스
따라서 z_fusion을 그대로 디코더 latent로 사용할 수 없습니다.
두 영역은 목적과 데이터 구조가 완전히 다르기 때문입니다.
이 간극을 메우는 기술이 바로 GPR → 모달 Latent Bridge입니다.
3. Addeep이 연구하는 Bridge 전략
Addeep은 다음 세 가지 전략을 조합하여 연구하고 있습니다.
3.1 Cross-Attention 기반 Global Conditioning
- z_fusion을 디코더 내부의 attention 구조에 직접 연결
- 브랜드·톤·마인드셋이 픽셀·프레임 수준까지 스며들도록 설계
- 장면 조화, 색감 일관성, 내러티브 흐름 전달에 효과적
특징
- 명시적으로 “이 장면은 이런 톤으로 가야 한다”는 제어가 가능
- 이미지·영상·오디오 모두에 범용적으로 적용 가능
3.2 Latent Prior Conditioning
- z_fusion이 생성 과정의 시작점(latent 분포)을 직접 결정
- 동일한 z_fusion이면 여러 모달이 동일한 세계관에서 생성
의미
- 브랜드 정체성, 사용자 감정 톤이 생성 과정의 출발점부터 반영됨
- 장면·컷 간 일관성 유지에 매우 유리
3.3 Slot 기반 중간 표현(Scene Slots)
z_fusion → Slot Transformer → K개의 의미 Slot 생성
예:
- Slot 1: 주요 인물
- Slot 2: 브랜드 영역
- Slot 3: 배경 세계관
- Slot 4: 텍스트/CTA 등장 위치
- Slot 5: 제품 사용 장면
Slot은 “의미 단위”를 공간·시간 구조로 변환하는 중간 계층입니다.
효과
- 이미지에서는 위치(좌표)로,
- 영상에서는 시간 구간으로,
- 오디오에서는 분위기·템포 변화로,
- 텍스트에서는 내러티브 단락으로 매핑할 수 있습니다.
즉, Slot 구조는
“광고·브랜드·사용자 맥락을 실제 생성물의 배치 구조로 바꾸는 핵심 기술”입니다.
4. 왜 Addeep은 ‘모달별 latent + GPR z-space’ 구조를 채택하는가
① Addeep의 핵심 가치는 의미 추론(z-space)에 있음
GPR·UMM·Mindset·ACT는 모두
사용자·콘텐츠·브랜드의 의미 구조를 정교하게 추론하는 데 초점을 둡니다.
② 디코더는 렌더링 계층(rendering layer)
각 모달은 고유한 물리적 구조를 갖고 있어
공통 latent를 강제하면 품질·안정성이 급격히 떨어집니다.
③ 확장성
이미지 → 영상 → 음원 → 텍스트 → 3D까지 확장 시,
각 디코더는 독립 진화하고
GPR → Bridge만 조정하면 전체 시스템이 확장됩니다.
④ 광고결합 스마트콘텐츠에 최적
브랜드 배치·제품 노출·장면 맥락·감정 톤 같은 제약을 가장 안정적으로 반영할 수 있는 구조입니다.
5. 모달별 Latent 구조 설계 방향
아래는 Addeep이 실제 연구 중인 모달별 Latent 설계 방향 요약입니다.
5.1 이미지 Latent 구조
- 2D 그리드 기반 latent
- z_fusion → global tone + local slot mapping
- 브랜드 영역은 Slot 기반으로 별도 강화
- 반복 편집에도 망가지지 않는 edit-robust 구조 연구
5.2 영상 Latent 구조
- 시간축(temporal) 구조 포함
- 장면 전개, 제품 등장 타이밍, 컷 전환 등
- Slot에 시간 범위를 부여하여 frame-level 조건화
5.3 음원 Latent 구조
- 시간–주파수 기반 latent
- 장면의 감정·속도·전환 구조를 audio motif로 변환
- 영상 frame-flow와 오디오 beat-flow를 정렬하는 구조 연구
5.4 텍스트 Latent 구조
- z_fusion을 LLM의 soft-prompt/pseudo-token으로 전달
- 감정·장면 톤·브랜드 화법을 일관되게 유지하도록 설계
- 텍스트는 구조적 제어가 가능한 모달이므로
장면 단위로 분리된 텍스트 역할(훅·설명·CTA)까지 encoding
6. Addeep GPR이 지향하는 멀티모달 생성 패러다임
Addeep이 지향하는 것은 “디코더가 잘 만드는 그림·영상·음악을 만드는 것” 자체가 아닙니다.
Addeep이 구축하는 생태계는,
사용자 마음의 변화(z_user) → 콘텐츠 의미(z_content) → 브랜드 정체성(z_brand) → 장면 구조(z_scene) → z_fusion → 모달별 생성
으로 이어지는 정합적 의미 체계 기반 생성 시스템입니다.
즉, Addeep은 멀티모달 생성기라기보다 “의미를 설계하는 엔진(Meaning Composition Engine)”에 가깝습니다.
이것이 바로 Addeep GPR 기술이 다른 생성 시스템과 구별되는 근본적인 차별점입니다.
© 2025 Addeep. All rights reserved.
본 문서에 포함된 개념, 아키텍처, 알고리즘, 용어 체계 및 기술적 서술은 모두 애딥(Addeep)의 고유한 지식재산권(IP)에 해당합니다.
애딥의 사전 서면 승인 없이 본 문서를 전부 또는 일부를 복제, 수정, 배포, 발췌, 인용, 2차 저작물로 활용하는 행위를 금합니다.
본 문서는 연구·제품·서비스 개발을 위한 애딥 내부 및 공식 협력 관계에서만 사용할 수 있습니다.

Leave a comment