안녕하세요. 오늘은 “GPR(Generative Pre-trained Recommender, 생성형 사전 학습 추천기)”과 “RSSM(Recurrent State Space Model, 순환 상태 공간 모델)”을 이해하기 위한, 일종의 최소 문법을 세팅하기 위한 글을 썼습니다.
기술이 고도화될수록 사람들은 자주 “AI가 데이터를 학습한다”라고 말하지만, 이 문장은 설명을 시작하는 말처럼 보이면서도 실제로는 생각을 멈추게 만드는 말이 되곤 합니다. 애딥의 관점에서 중요한 건 “데이터를 많이 먹이면 된다”가 아니라, “AI가 무엇을 ‘배운다고 착각’하고 무엇을 ‘실제로’ 배우는가”를 구분하는 일입니다. 이 구분이 안 되면, 왜 GPR이 단순 예측기를 넘어 정책 엔진으로 설계되는지, 왜 RSSM 같은 상태 모델이 ‘선택’이 아니라 ‘필수’가 되는지, 결국 설계의 이유가 안 보입니다.
이 글의 목표는 한 가지입니다. 모델을 블랙박스로 숭배하지 않고, 의미가 조립되고 상태가 전이되는 내부 구조를 “읽을 수 있는 눈”을 만드는 것입니다.
1. AI는 데이터를 학습하지 않는다: 데이터, 패턴, 확률
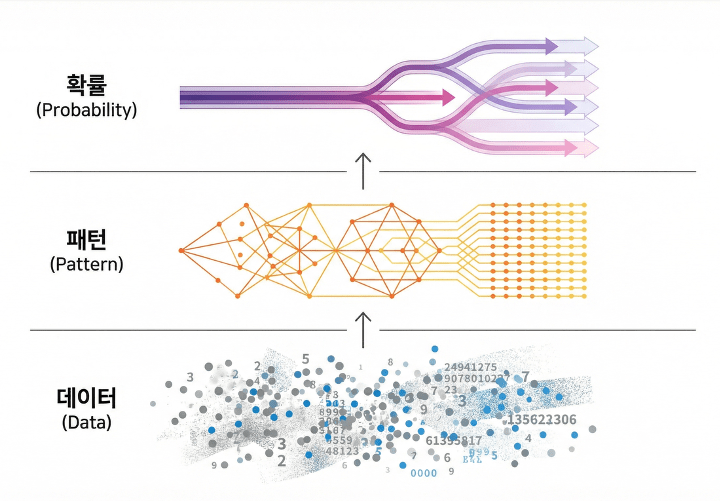
우리가 흔히 부르는 데이터는 “세계 그 자체”가 아니라 “관측의 기록”입니다. 관측에는 설계가 개입합니다. 무엇을 측정할지, 어떤 단위로 남길지, 무엇을 이벤트로 정의할지, 그 선택이 데이터의 모양을 결정합니다. 특히 추천·광고 영역의 로그는 더 노골적입니다. 사용자가 ‘자발적으로’ 한 행동의 기록이 아니라, 시스템이 먼저 노출한 결과에 대한 반응 기록이기 때문입니다. 즉, 로그에는 사용자의 취향뿐 아니라 “시스템의 선택 습관”이 함께 들어 있습니다. 그래서 데이터는 정답이 아니라 증거이고, 증거는 언제나 누락과 편향을 품습니다.
그다음 층이 패턴입니다. 패턴은 개별 사건을 넘어, 반복되는 구조가 압축된 형태입니다. 모델의 매개변수(Parameter)는 데이터를 저장하는 게 아니라, 데이터가 보여준 반복 구조를 저장합니다. 여기서 중요한 건, 패턴이 곧 의미가 아니라는 점입니다. 패턴은 상관관계일 수 있고, 관측 시스템이 만든 가짜 규칙성일 수도 있고, 실제 원인 구조의 일부를 반영했을 수도 있습니다. 패턴은 “왜”보다 “자주 함께 나타남”을 먼저 말합니다.
마지막 층이 확률입니다. 확률은 패턴의 강도를 수치화한 표현입니다. 많은 오해가 여기서 생깁니다. 확률이 높다는 건 흔히 “정답에 가깝다”로 받아들여지지만, 실제로는 “학습 데이터 분포에 잘 맞는다”에 가깝습니다. 그리고 확률은 목적 함수에 의해 방향이 결정됩니다. CTR(Click-Through Rate, 클릭률)을 최적화하면 클릭을 유발하는 패턴이 강화되고, 그 결과는 확률적으로 성공인데 의미적으로 실패(피로, 불신, 이탈)일 수 있습니다.
정리하면 이렇습니다.
- 데이터는 관측의 부산물(편향·누락 포함)
- 패턴은 반복 구조(의미 보장 아님)
- 확률은 분포 적합도(진실/가치 보장 아님)
이 3개 층을 분해를 하면, 다음 질문이 자연스럽게 생깁니다.
“그럴듯함”이 아니라 “지금 이 상황에 맞음”을 다루려면 무엇이 추가되어야 하는가?
2. 토큰(Token, 토큰)은 의미가 아니라 계산을 위한 분해 단위
AI는 연속된 세계를 그대로 처리하지 못합니다. 그래서 현실을 잘게 나누어 목록화하고, 그 최소 단위를 토큰(Token, 토큰)이라 부릅니다. 토큰은 의미 단위라기보다 계산 단위입니다. 텍스트에서는 단어/음절/서브워드(Subword)처럼, 이미지에서는 패치(Patch)처럼, 영상에서는 프레임 단위 조각처럼, 음성에서는 짧은 시간 구간처럼 쪼개서 들어갑니다.
애딥 관점에서 중요한 포인트는 토큰이 콘텐츠에만 국한되지 않는다는 겁니다. 행동 로그에서도 클릭, 스크롤, 시청, 체류 같은 이벤트가 토큰이 됩니다. “응시_3초” 같은 형태의 사건 토큰들이 쌓여 시퀀스(Sequence)를 만듭니다.
하지만 토큰은 상태(State)가 아니라 관측(Observation)입니다. 토큰 시퀀스를 잘 예측하는 모델이 “다음에 뭐가 올지”는 잘 맞혀도, “지금 어떤 상태인지”를 명확히 말하지 못하는 이유가 여기서 출발합니다. 상태를 다루려면, 토큰 위에 다른 층이 필요합니다.
3. 벡터와 임베딩은 ‘의미’가 아니라 ‘좌표’다
토큰은 기호이기 때문에, 컴퓨터가 계산하려면 숫자가 되어야 합니다. 토큰이 벡터(Vector)로 변환되는 과정이 임베딩(Embedding)입니다. 여기서 반드시 잡아야 할 관점은 이겁니다.
임베딩 벡터는 의미를 담는 저장소가 아니라,
의미가 드러나도록 배치된 좌표다.
가깝다는 건 “비슷한 맥락에서 자주 등장했다”는 통계적 유사성이고, 멀다는 건 다른 맥락에서 쓰였다는 뜻입니다. 코사인 유사도(Cosine Similarity) 같은 지표는 그 관계를 수치화한 방법일 뿐입니다.
애딥의 GPR 시스템은 멀티모달을 하나의 좌표계로 모으려 합니다. 텍스트, 이미지/영상, 행동 이벤트, 상품/광고 메타가 같은 의미 체계에서 만날 수 있어야 “추천-생성-커머스”가 하나로 묶이기 때문입니다. 그리고 이 통합 좌표계는 “의미를 이해했다”의 증거가 아니라, “의미처럼 보이게 만드는 수치적 배치”라는 점을 계속 경계해야 합니다. 왜냐하면 좌표는 목적 함수에 따라 달라지고, 목적이 바뀌면 세계도 바뀌기 때문입니다.
4. 잠재 공간은 ‘보이지 않는 상태’를 다루기 위한 무대
임베딩이 관측을 옮긴 표현이라면, 잠재 공간(Latent Space)은 관측 뒤에 있는 상태를 다루기 위한 공간입니다. 인간의 세계에서 중요한 건 종종 관측이 아니라 그 관측을 만들어낸 내부 상태입니다. 동일한 클릭이라도 충동인지, 비교인지, 구매 직전인지 의미가 달라집니다. 이 차이는 관측의 차이가 아니라 상태의 차이입니다.
잠재 공간을 도입하면, 모델은 관측을 바로 반응하지 않고 “상태를 추정한 뒤 그 상태로 판단”할 수 있습니다. 여기서 잠재 공간은 단순 압축 저장소가 아니라, 추론과 시뮬레이션이 벌어지는 무대가 됩니다. 여러 가능성을 비교하고, 미래 상태를 상상하고, 불확실성을 분포로 들고 가는 일이 가능해집니다.
이 지점이 월드 모델·RSSM로 넘어가는 다리입니다. “상태를 다루는 모델링”이 없으면, 의미적으로 맞는 판단은 구조적으로 불가능해집니다.
5. “확률적으로 그럴듯함”과 “의미적으로 맞음”은 다르다
현대 AI의 인상적인 성능은 대개 “그럴듯함”에서 옵니다. 자연스러운 문장, 그럴싸한 이미지, 높은 클릭 예측. 하지만 그럴듯함은 분포에 맞는다는 뜻이고, 의미적으로 맞음은 목적·맥락·가치·제약과 일치한다는 뜻입니다.
추천을 예로 들면, 같은 클릭 반복은 CTR을 올리지만, 사용자가 이미 비교를 끝냈다면 의미적으로는 “결정 도움”이 더 맞을 수 있습니다. 생성 모델도 마찬가지입니다. 시각적으로 좋은 결과물이 브랜드 가이드나 캠페인 맥락에 맞는지는 별개의 문제입니다.
그래서 애딥이 강조하는 방향은 “확률 위에 상태를 얹는 것”입니다. 의미적으로 맞는 선택은 상태 기반 판단입니다. 그리고 상태는 단일 관측으로 드러나지 않으므로, 시간에 걸쳐 축적·전이되어야 합니다. 이게 바로 RSSM(Recurrent State Space Model, 순환 상태 공간 모델)이 필요한 이유로 이어집니다.
6. NEXT – 시퀀스 모델을 통해 시간을 구조로 다루는 이야기
다음은 인공지능이 시간을 어떻게 다뤄왔는지를 시퀀스 모델의 관점에서 설명하는 글을 작성할 예정입니다. 여기서 시간은 입력에 덧붙여지는 부가 정보가 아니라, 모델의 사고 방식 자체를 규정하는 구조입니다. 인간의 언어, 행동, 선택은 모두 단일 순간의 사건이 아니라 과거와 현재, 그리고 미래 기대가 연결된 흐름 위에서 의미를 갖습니다. 시퀀스를 이해한다는 것은 이 흐름 속에서 무엇이 유지되고 무엇이 사라지며, 어떤 정보가 다음 판단에 영향을 미치는지를 모델 내부 구조로 표현하는 일입니다.
다음 글에서는 순환 신경망(Recurrent Neural Network)이 왜 등장했는지를 다룹니다. 이어서 장단기 기억 네트워크(Long Short-Term Memory)와 게이트 순환 유닛(Gated Recurrent Unit)이 어떤 한계를 해결하려 했는지를 설명합니다. 또한 트랜스포머(Transformer)가 시간 처리 방식에서 무엇을 혁신했고 무엇을 남겨두었는지를 차례로 살펴봅니다. 이를 통해 시퀀스를 처리하는 문제가 단순한 모델 성능의 문제가 아니라, 기억과 망각, 맥락과 상태를 어떻게 정의하느냐의 문제임을 드러냅니다.
이 과정의 목적은 특정 아키텍처를 비교하거나 외우는 데 있지 않습니다. 핵심은 왜 시퀀스 문제가 기존의 확률 기반 접근만으로는 충분하지 않은지를 이해하는 데 있습니다. 또한 시간 위에서 변화하는 상태를 명시적으로 다룰 수 있는 구조가 왜 필요해지는지를 인식하는 데 있습니다. 이러한 이해가 쌓일수록 이후에 등장하는 SSM(State Space Model, 상태 공간 모델)과 RSSM(Recurrent State Space Model, 순환 상태 공간 모델)이 단순한 고급 기법이 아니라 필연적인 선택으로 보이게 될 것입니다.

Leave a comment